Как создать файл Robots.txt: настройка, проверка, индексация | IM

В SEO мелочей не бывает. Иногда на продвижение сайта может оказать влияние всего лишь один небольшой файл — Robots.txt. Если вы хотите, чтобы ваш сайт зашел в индекс, чтобы поисковые роботы обошли нужные вам страницы, нужно прописать для них рекомендации.
«Разве это возможно?», — спросите вы. Возможно. Для этого на вашем сайте должен быть файл robots.txt. Как правильно составить файл роботс, настроить и добавить на сайт – разбираемся в этой статье.
Что такое robots.txt и для чего нужен
Robots.txt – это обычный текстовый файл, который содержит в себе рекомендации для поисковых роботов: какие страницы нужно сканировать, а какие нет.
Важно: файл должен быть в кодировке UTF-8, иначе поисковые роботы могут его не воспринять.
Зайдет ли в индекс сайт, на котором не будет этого файла? Зайдет, но роботы могут «выхватить» те страницы, наличие которых в результатах поиска нежелательно: например, страницы входа, админпанель, личные страницы пользователей, сайты-зеркала и т.п. Все это считается «поисковым мусором»:
Если в результаты поиска попадёт личная информация, можете пострадать и вы, и сайт. Ещё один момент – без этого файла индексация сайта будет проходить дольше.
В файле Robots.txt можно задать три типа команд для поисковых пауков:
- сканирование запрещено;
- сканирование разрешено;
- сканирование разрешено частично.
Все это прописывается с помощью директив.
Как создать правильный файл Robots.txt для сайта
Файл Robots.txt можно создать просто в программе «Блокнот», которая по умолчанию есть на любом компьютере. Прописывание файла займет даже у новичка максимум полчаса времени (если знать команды).
Также можно использовать другие программы – Notepad, например. Есть и онлайн сервисы, которые могут сгенерировать файл автоматически. Например, такие как CY-PR.com или Mediasova.

Вам просто нужно указать адрес своего сайта, для каких поисковых систем нужно задать правила, главное зеркало (с www или без). Дальше сервис всё сделает сам.
Лично я предпочитаю старый «дедовский» способ – прописать файл вручную в блокноте. Есть ещё и «ленивый способ» — озадачить этим своего разработчика 🙂 Но даже в таком случае вы должны проверить, правильно ли там всё прописано. Поэтому давайте разберемся, как составить этот самый файл, и где он должен находиться.
Это интересно: Как увеличить посещаемость сайта
Где должен находиться файл Robots
Готовый файл Robots.txt должен находиться в корневой папке сайта. Просто файл, без папки:
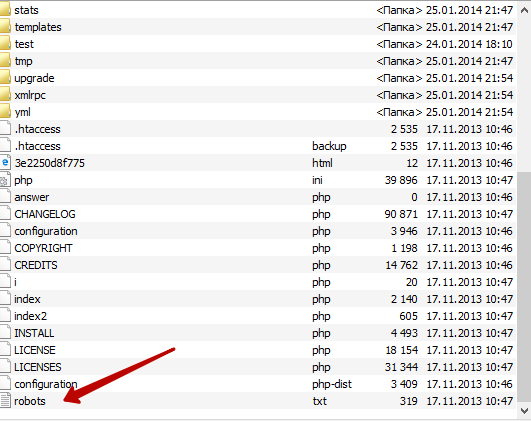
Хотите проверить, есть ли он на вашем сайте? Вбейте в адресную строку адрес: site.ru/robots.txt. Вам откроется вот такая страничка (если файл есть):

Файл состоит из нескольких блоков, отделённых отступом. В каждом блоке – рекомендации для поисковых роботов разных поисковых систем (плюс блок с общими правилами для всех), и отдельный блок со ссылками на карту сайта – Sitemap.
Внутри блока с правилами для одного поискового робота отступы делать не нужно.
Каждый блок начинается директивой User-agent.
После каждой директивы ставится знак «:» (двоеточие), пробел, после которого указывается значение (например, какую страницу закрыть от индексации).
Нужно указывать относительные адреса страниц, а не абсолютные. Относительные – это без «www.site.ru». Например, вам нужно запретить к индексации страницу www.site.ru/shop. Значит после двоеточия ставим пробел, слэш и «shop»:
Disallow: /shop.
Звездочка (*) обозначает любой набор символов.
Знак доллара ($) – конец строки.
Вы можете решить – зачем писать файл с нуля, если его можно открыть на любом сайте и просто скопировать себе?
Для каждого сайта нужно прописывать уникальные правила. Нужно учесть особенности CMS. Например, та же админпанель находится по адресу /wp-admin на движке WordPress, на другом адрес будет отличаться. То же самое с адресами отдельных страниц, с картой сайта и прочим.
Настройка файла Robots.txt: индексация, главное зеркало, диррективы
Как вы уже видели на скриншоте, первой идет директива User-agent. Она указывает, для какого поискового робота будут идти правила ниже.
User-agent: * — правила для всех поисковых роботов, то есть любой поисковой системы (Google, Yandex, Bing, Рамблер и т.п.).
User-agent: Googlebot – указывает на правила для поискового паука Google.
User-agent: Yandex – правила для поискового робота Яндекс.
Для какого поискового робота прописывать правила первым, нет никакой разницы. Но обычно сначала пишут рекомендации для всех роботов.
Рекомендации для каждого робота, как я уже писала, отделяются отступом.
Disallow: Запрет на индексацию
Чтобы запретить индексацию сайта в целом или отдельных страниц, используется директива Disallow.
Например, вы можете полностью закрыть сайт от индексации (если ресурс находится на доработке, и вы не хотите, чтобы он попал в выдачу в таком состоянии). Для этого нужно прописать следующее:
User-agent: *
Disallow: /
Таким образом всем поисковым роботам запрещено индексировать контент на сайте.
А вот так можно открыть сайт для индексации:
User-agent: *
Disallow:
Потому проверьте, стоит ли слеш после директивы Disallow, если хотите закрыть сайт. Если хотите потом его открыть – не забудьте снять правило (а такое часто случается).
Чтобы закрыть от индексации отдельные страницы, нужно указать их адрес. Я уже писала, как это делается:
User-agent: *
Disallow: /wp-admin
Таким образом на сайте закрыли от сторонних взглядов админпанель.
Что нужно закрывать от индексации в обязательном порядке:
- административную панель;
- личные страницы пользователей;
- корзины;
- результаты поиска по сайту;
- страницы входа, регистрации, авторизации.
Можно закрыть от индексации и отдельные типы файлов. Допустим, у вас на сайте есть некоторые .pdf-файлы, индексация которых нежелательна. А поисковые роботы очень легко сканируют залитые на сайт файлы. Закрыть их от индексации можно следующим образом:
User-agent: *
Disallow: /*. pdf$
Как отрыть сайт для индексации
Даже при полностью закрытом от индексации сайте можно открыть роботам путь к определённым файлам или страницам. Допустим, вы переделываете сайт, но каталог с услугами остается нетронутым. Вы можете направить поисковых роботов туда, чтобы они продолжали индексировать раздел. Для этого используется директива Allow:
User-agent: *
Allow: /uslugi
Disallow: /
Главное зеркало сайта
До 20 марта 2018 года в файле robots.txt для поискового робота Яндекс нужно было указывать главное зеркало сайта через директиву Host. Сейчас этого делать не нужно – достаточно настроить постраничный 301-редирект.
Что такое главное зеркало? Это какой адрес вашего сайта является главным – с www или без. Если не настроить редирект, то оба сайта будут проиндексированы, то есть, будут дубли всех страниц.
Карта сайта: robots.txt sitemap
После того, как прописаны все директивы для роботов, необходимо указать путь к Sitemap. Карта сайта показывает роботам, что все URL, которые нужно проиндексировать, находятся по определённому адресу. Например:
Sitemap: site.ru/sitemap.xml
Когда робот будет обходить сайт, он будет видеть, какие изменения вносились в этот файл. В итоге новые страницы будут индексироваться быстрее.
Читайте по теме: Как сделать карту сайта
Директива Clean-param
В 2009 году Яндекс ввел новую директиву – Clean-param. С ее помощью можно описать динамические параметры, которые не влияют на содержание страниц. Чаще всего данная директива используется на форумах. Тут возникает много мусора, например id сессии, параметры сортировки. Если прописать данную директиву, поисковый робот Яндекса не будет многократно загружать информацию, которая дублируется.
Прописать эту директиву можно в любом месте файла robots.txt.
Параметры, которые роботу не нужно учитывать, перечисляются в первой части значения через знак &:
Clean-param: sid&sort /forum/viewforum.php
Эта директива позволяет избежать дублей страниц с динамическими адресами (которые содержат знак вопроса).
Директива Crawl-delay
Эта директива придёт на помощь тем, у кого слабый сервер.
Приход поискового робота – это дополнительная нагрузка на сервер. Если у вас высокая посещаемость сайта, то ресурс может попросту не выдержать и «лечь». В итоге робот получит сообщение об ошибке 5хх. Если такая ситуация будет повторяться постоянно, сайт может быть признан поисковой системой нерабочим.
Представьте, что вы работаете, и параллельно вам приходится постоянно отвечать на звонки. Ваша продуктивность в таком случае падает.
Так же и с сервером.
Вернемся к директиве. Crawl-delay позволяет задать задержку сканирования страниц сайта с целью снизить нагрузку на сервер. Другими словами, вы задаете период, через который будут загружаться страницы сайта. Указывается данный параметр в секундах, целым числом:
Crawl-delay: 2
Комментарии в robots.txt
Бывают случаи, когда вам нужно оставить в файле комментарий для других вебмастеров. Например, если ресурс передаётся в работу другой команде или если над сайтом работает целая команда.
В этом файле, как и во всех других, можно оставлять комментарии для других разработчиков.
Делается это просто – перед сообщением нужно поставить знак решетки: «#». Дальше вы можете писать свое примечание, робот не будет учитывать написанное:
User-agent: *
Disallow: /*. xls$
#закрыл прайсы от индексации
Как проверить файл robots.txt
После того, как файл написан, нужно узнать, правильно ли. Для этого вы можете использовать инструменты от Яндекс и Google.
Через Яндекс.Вебмастер robots.txt можно проверить на вкладке «Инструменты – Анализ robots.txt»:
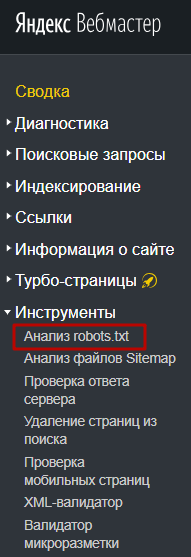
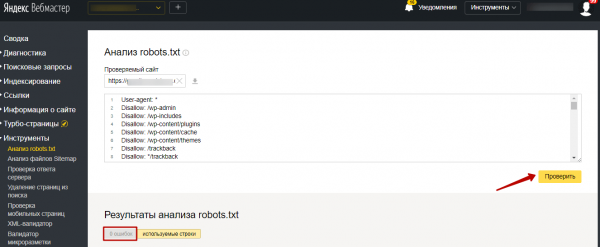
На открывшейся странице указываем адрес проверяемого сайта, а в поле снизу вставляем содержимое своего файла. Затем нажимаем «Проверить». Сервис проверит ваш файл и укажет на возможные ошибки:
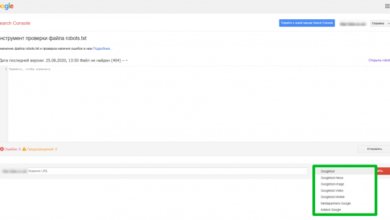
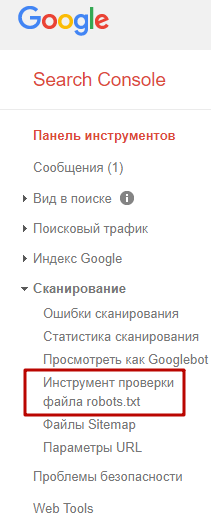
Также можно проверить файл robots.txt через Google Search Console, если у вас подтверждены права на сайт.
Для этого в панели инструментов выбираем «Сканирование – Инструмент проверки файла robots.txt».
На странице проверки вам тоже нужно будет скопировать и вставить содержимое файла, затем указать адрес сайта:
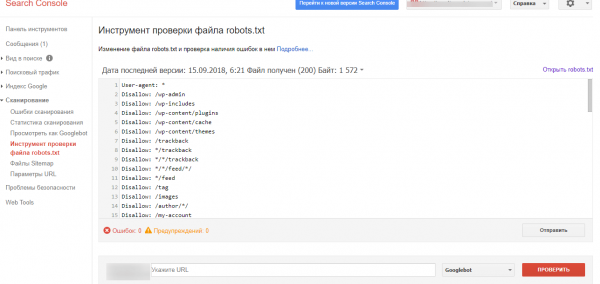
Потом нажимаете «Проверить» — и все. Система укажет ошибки или выдаст предупреждения.
Останется только внести необходимые правки.
Если в файле присутствуют какие-то ошибки, или появятся со временем (например, после какого-то очередного изменения), инструменты для вебмастеров будут присылать вам уведомления об этом. Извещение вы увидите сразу, как войдете в консоль.
Это интересно: 20 самых распространённых ошибок, которые убивают ваш сайт
Частые ошибки в заполнении файла robots.txt
Какие же ошибки чаще всего допускают вебмастера или владельцы ресурсов?
1. Файла вообще нет. Это встречается чаще всего, и выявляется при SEO-аудите ресурса. Как правило, на тот момент уже заметно, что сайт индексируется не так быстро, как хотелось бы, или в индекс попали мусорные страницы.
2. Перечисление нескольких папок или директорий в одной инструкции. То есть вот так:
Allow: /catalog /uslugi /shop
Называется «зачем писать больше…». В таком случае робот вообще не знает, что ему можно индексировать. Каждая инструкция должна иди с новой строки, запрет или разрешение на индексацию каждой папки или страницы – это отдельная рекомендация.
3. Разные регистры. Название файла должно быть с маленькой буквы и написано маленькими буквами – никакого капса. То же самое касается и инструкций: каждая с большой буквы, все остальное – маленькими. Если вы напишете капсом, это будет считаться уже совсем другой директивой.
4. Пустой User-agent. Нужно обязательно указать, для какой поисковой системы идет набор правил. Если для всех – ставим звездочку, но никак нельзя оставлять пустое место.
5. Забыли открыть ресурс для индексации после всех работ – просто не убрали слеш после Disallow.
6. Лишние звездочки, пробелы, другие знаки. Это просто невнимательность.
Регулярно заглядывайте в инструменты для вебмастеров и вовремя исправляйте возможные ошибки в своем файле robots.txt.
Удачного вам продвижения!